
Вы специалист по безопасности или аналитик, которому нужно быстро классифицировать большой список веб-сайтов?
А может быть, вы просто хотите проанализировать несколько доменов для собственного исследования.
Ручная проверка категории каждого сайта в инструменте Symantec Site Review может быть очень утомительной и отнимать много времени.
Чтобы помочь в этом, мы создали удобный Python-скрипт, который может автоматизировать процесс категоризации сайтов в массовом порядке с помощью базы данных Symantec.
В этом руководстве мы объясним, что такое инструмент Site Review, как работает наш скрипт, что требуется для его запуска и пошаговые инструкции, чтобы начать массово классифицировать веб-сайты.
Бесплатный инструмент Symantec Site Review позволяет вручную проверить категорию URL-адреса любого веб-сайта по их базе данных.
Он позволяет выявить более 60 типов контента, таких как азартные игры, разжигание ненависти, ботнеты, вредоносное ПО и т. д.
Это помогает службам безопасности классифицировать и фильтровать веб-сайты во время расследований.
- Краткая справка об инструменте Symantec Site Review Tool
- О скрипте массовой категоризации веб-сайтов domain_categorization.py
- Ниже приведен общий обзор того, как это работает:
- Необходимые условия для запуска скрипта
- Пошаговое руководство по проверке веб-сайтов в массовом порядке
- Заполните входной файл
- Выполните скрипт
- Просмотр результатов
Краткая справка об инструменте Symantec Site Review Tool
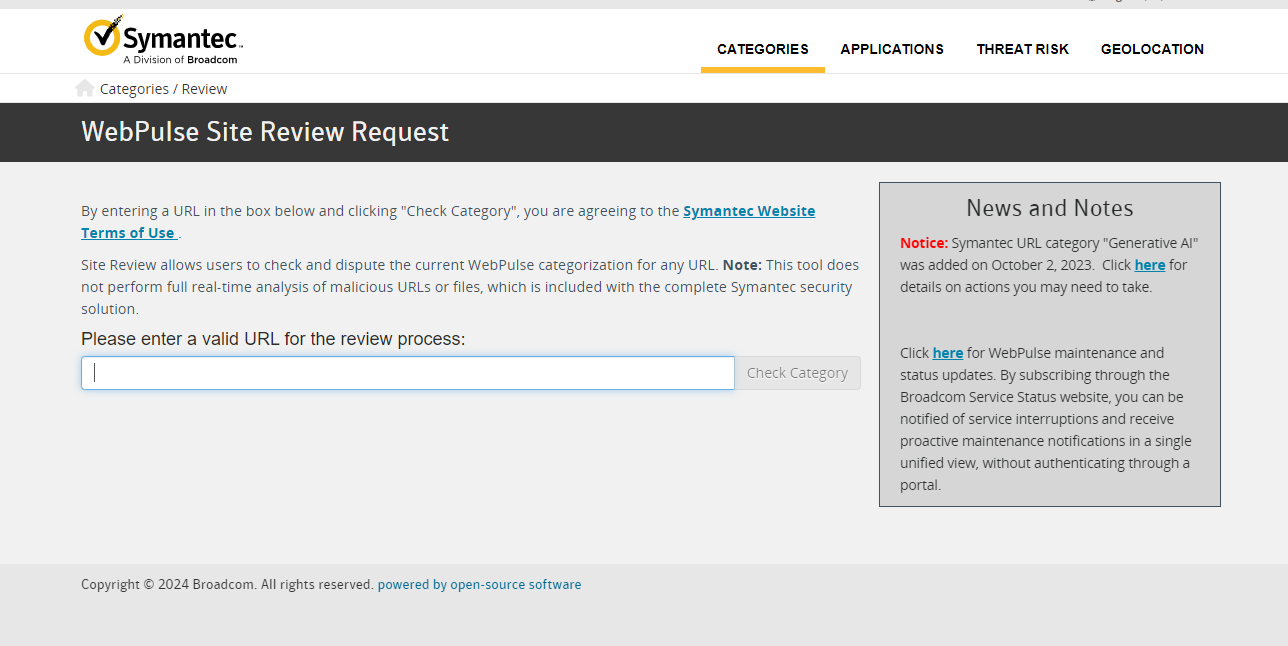
Инструмент очень полезен, но имеет некоторые ограничения по возможностям.
Он предназначен для ручных разовых проверок, а не для массовых автоматических отправок.
Отправка более 500 URL-адресов подряд может привести к срабатыванию CAPTCHA, которые блокируют дальнейшие автоматические запросы.
Мы настоятельно рекомендуем избегать автоматической отправки тысяч URL-адресов за короткий промежуток времени.
В этом случае ресурсы Site Review будут использоваться не по назначению.
Вместо этого используйте наш скрипт для категоризации сайтов партиями менее 100 URL.
Дайте пройти достаточно времени, прежде чем запускать более крупные списки.
При разумном использовании инструмент может принести пользу вашему рабочему процессу категоризации веб-сайтов.
Но помните о его ограничениях и не злоупотребляйте бесплатным ресурсом.
О скрипте массовой категоризации веб-сайтов domain_categorization.py
Чтобы помочь автоматизировать инструмент Symantec Site Review для массовых проверок, есть скрипт на языке Python под названием domain_categorization.py.
# Import Selenium webdriver and support classes
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Open input file and read domains into list
with open('domains.txt') as f:
domains = f.read().splitlines()
# Open output file for writing results
with open('results.txt', 'w') as out_file:
# Open captcha file for writing CAPTCHA detections
with open('captcha.txt', 'a') as captcha_file:
# Iterate through each domain
for domain in domains:
# Launch headless Chrome browser
browser = webdriver.Chrome()
# Navigate to the website
browser.get("https://sitereview.bluecoat.com/#/")
# Set default name variable
name = domain
# Find search box, input domain, hit Enter
search_box = browser.find_element(By.ID, "txtUrl")
search_box.clear()
search_box.send_keys(domain)
search_box.send_keys(Keys.RETURN)
# Check for CAPTCHA
try:
captcha = WebDriverWait(browser, 2).until(EC.presence_of_element_located((By.ID, "imgCaptcha")))
captcha_message = f"Captcha detected for domain {domain}. Stopping execution.\n"
print(captcha_message)
captcha_file.write(captcha_message)
browser.quit()
continue
except:
pass # No captcha found, continue execution
# Try getting details of a categorized domain
try:
elm1 = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.ID, "lnkRatedSite")))
elm2 = browser.find_element(By.ID, "txtUrlShortener")
# Check for URL shortener page
if elm2:
categories = "The URL you entered is a URL shortening service"
else:
# Extract name and categories from elements
name = elm1.text
categories = ",".join([x.text for x in browser.find_elements(By.CLASS_NAME, "clickable-category")])
except:
# If error, try checking for uncategorized domain page
try:
elm = browser.find_element(By.CLASS_NAME, "url-display")
if "ng-star-inserted" in elm.get_attribute("class"):
categories = ",".join([x.text for x in browser.find_elements(By.CLASS_NAME, "clickable-category")])
else:
categories = "This_URL_has_not_yet_been_rated"
except:
# If no match, set default category text
categories = "This_URL_has_not_yet_been_rated"
# Write domain results to output file
out_file.write(f"{domain},{categories}\n")
# Close browser instance
browser.quit()
print("Scraping complete, output saved in results.txt")
Он обрабатывает отправку нескольких URL-адресов на сайт Site Review, анализирует результаты категоризации и компилирует их в удобный для анализа текстовый файл.
Ниже приведен общий обзор того, как это работает:
Скрипт начинается с открытия списка URL-адресов, которые вы хотите проверить, из файла domains.txt.
Затем он запускает браузер Chrome с помощью Selenium, программно переходя на веб-страницу инструмента Site Review.
Он берет первый URL-адрес из списка, вводит его в поле поиска на сайте Site Review и нажимает клавишу Enter, чтобы отправить сайт на категоризацию.
По мере обработки каждого URL-адреса он проверяет наличие всплывающих окон CAPTCHA и обрабатывает их соответствующим образом.
Как только URL-адрес классифицирован, скрипт извлекает идентифицированные категории и доменное имя в переменные.
Вместе с исходным URL он записывает все в выходной файл results.txt.
Этот процесс извлечения повторяется для каждого URL из входного списка.
Все URL-адреса, прошедшие CAPTCHA, записываются отдельно в файл captcha.txt для последующей ручной перепроверки.
В целом это автоматизированное взаимодействие с сайтом Site Review позволяет вводить массовый список URL-адресов и эффективно получать категории сайтов, разобранные в текстовом файле.
Это экономит огромное количество времени на ручной анализ.
Вот его ключевые особенности:
- Массовая обработка URL-адресов: Разбирает текстовый файл с URL-адресами и проверяет категории для каждого из них через сайт инструмента Site Review.
- Обработка CAPTCHA: Автоматически обнаруживает и обрабатывает CAPTCHA, если они появляются, и регистрирует все заблокированные URL.
- Ведение журнала результатов: Сохраняет данные о категоризированных URL в файле результатов .txt для удобства анализа. Также регистрируются все случаи появления CAPTCHA.
В целом, он делает проверку сотен или тысяч сайтов быстрым и безболезненным процессом!
Необходимые условия для запуска скрипта
Перед запуском скрипта domain_categorization.py для категоризации веб-сайтов вам необходимо установить:
Окружение Python: Для выполнения скрипта .py необходимо, чтобы на вашем компьютере был установлен Python 3.x.
Загрузите последнюю версию 3.x, если у вас ее еще нет, с сайта https://www.python.org/downloads/.
Модуль Selenium: Скрипт импортирует Selenium для автоматизации взаимодействия с браузером.
Установите его через pip, запустив:
ChromeDriver: ChromeDriver позволяет Selenium взаимодействовать с Google Chrome.
Загрузите драйвер с сайта https://chromedriver.chromium.org/downloads и добавьте его исполняемый файл в системный PATH.
Убедитесь, что вы взяли версию ChromeDriver, соответствующую версии установленного браузера Chrome.
Входной файл: подготовьте список URL-адресов в обычном текстовом файле domains.txt.
Поместите в этот файл по одному URL в строке, чтобы скрипт мог перебирать их.
Как только Python, Selenium, ChromeDriver и список входных URL будут готовы, вы можете приступать к запуску скрипта проверки категории сайта!
Сообщите нам, если какие-либо предварительные условия неясны.
Пошаговое руководство по проверке веб-сайтов в массовом порядке
Как только все необходимые условия будут созданы, вы будете готовы использовать скрипт для массовой категоризации списков веб-сайтов.
Следуйте этому упорядоченному процессу:
Заполните входной файл
Добавьте полные URL-адреса, которые вы хотите проверить, по одному в каждую строку, в текстовый файл domains.txt.
Он служит в качестве входного списка, который скрипт будет просматривать.
Выполните скрипт
Откройте терминал или командную строку, перейдите в каталог скрипта и запустите его:
Система запустит автоматизацию браузера Selenium, чтобы начать проверку каждого URL-адреса с помощью инструмента Symantec Site Review.
Просмотр результатов
По мере выполнения скрипта результаты категоризации URL будут построчно компилироваться в файл results.txt.
Любые CAPTCHA, обнаруженные в середине процесса, будут занесены в файл captcha.txt для последующего повторения.
см. также:
- 🐍 Инструкция и скрипт на Python по брутфорсу FTP
- 🐍 Программа на Python для загрузки JSON-данных из файла
- 🐍 Как использовать Bandit для проверки кода Python на наличие уязвимостей
- 🐍 Вычисление контрольных сумм с помощью Python и Hashlib
- 🐍 SQL и Python: Как применяются вместе?
- 🐍 Как получить доступ к переменным среды в Python







