Давайте узнаем, как обеспечить надежность своего прода с помощью инструментов Chaos Engineering.
Хаос-инжиниринг – это направление, в которой вы экспериментируете над своей системой или приложением, чтобы выявить их слабые места и отказ производительности.
Таким образом, вы намеренно вызываете некоторые сбои в своей системе, чтобы выявить ее слабые места, чтобы внести исправления и сделать вашу систему и приложение более устойчивыми.
Многие популярные организации, такие как Netflix, LinkedIn и Facebook, занимаются проектированием хаос инструментов, чтобы лучше понять архитектуру своих микросервисов и распределенные системы.
Это помогает находить новые проблемы раньше, чем настоящие жалобы пользователей, и принимать необходимые меры для их исправления.
Таким образом эти организации могут обслуживать миллионы пользователей, повышать производительность и экономить миллионы долларов 🤑.
Преимущества Chaos Engineering:
- Контролируйте потери доходов, обнаруживая критические проблемы
- Уменьшение количества отказов системы или приложений
- Лучшее взаимодействие с пользователем с меньшим количеством сбоев и высокой доступностью служб
- Это поможет вам узнать о системе и обрести уверенность.
Насколько вы уверены в надежности своего прода?
Давайте узнаем это с помощью следующих популярных инструментов для хаос тестирования.
Chaos Mesh
Chaos Mesh – это решение для управления хаос тестами, которое вводит ошибки на каждом уровне системы Kubernetes.
Сюда входят поды, сеть, системный ввод-вывод и ядро.
Chaos Mesh может автоматически убивать поды Kubernetes, имитируя задержки.
Он может нарушить обмен данными между подами и имитировать ошибки чтения/записи.
Он может планировать правила для экспериментов и определять их объем.
Эти эксперименты указаны с использованием файлов YAML.
Chaos Mesh имеет панель инструментов для просмотра аналитики экспериментов.
Он работает поверх Kubernetes и поддерживает большую часть облачной платформы.
Это проект с открытым исходным кодом, который недавно был принят как проект песочницы CNCF.
Вы можете добавить Chaos Mesh в свой рабочий процесс DevOps, чтобы создавать устойчивые приложения, используя принципы хаос-инженерии.
Особенности Chaos Mesh:
- Легко разворачивается на кластерах Kubernetes без изменения логики развертывания
- Для развертывания не требуются уникальные зависимости
- Определяет объекты хаоса с помощью CustomResourceDefinitions (CRD)
- Предоставляет панель для отслеживания всех экспериментов
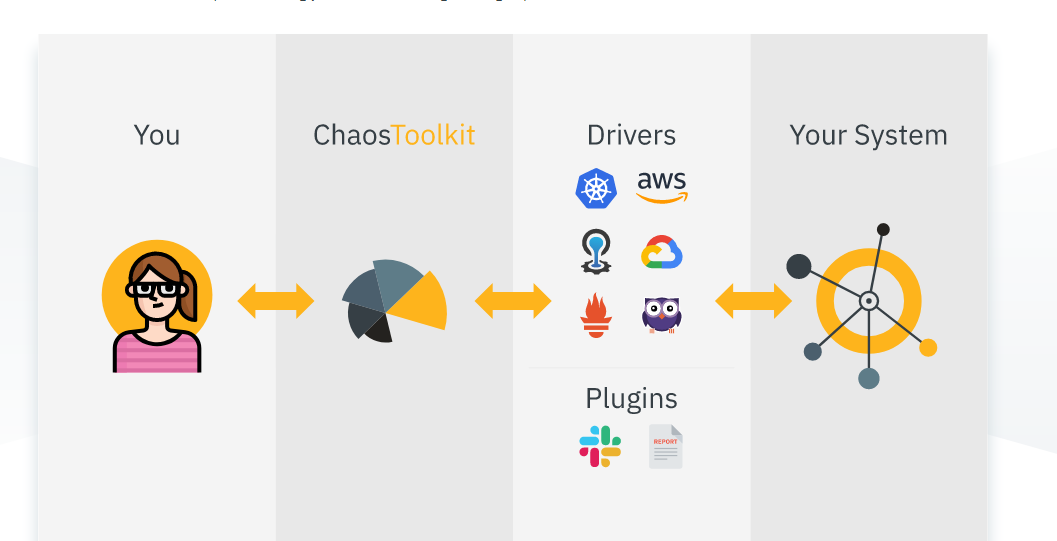
Chaos ToolKit – это простой инструмент с открытым исходным кодом для автоматизации экспериментов Chaos Engineering.
Вы интегрируете Chaos ToolKit в свою систему с помощью набора драйверов или плагинов, которые он поддерживает AWS, Google Cloud, Slack, Prometheus и т. д.
- Предоставляет декларативный открытый API для создания хаос-экспериментов независимо от поставщика или технологии
- Легко встраивается в пайплайны CICD для автоматизации
- Предоставляет коммерческую и корпоративную поддержку также через ChaosIQ
ChaosKube

Как можно догадаться по названию, это для Kubernetes.
Chaoskube – это инструмент хаос инжиниринга с открытым исходным кодом, который периодически убивает случайные поды в кластере Kubernetes.
Он поможет вам понять, как ваша система отреагирует на отказ пода.
По умолчанию он убивает под в любом пространстве имен каждые 10 минут.
Вы можете фильтровать целевые поды в Chaoskube, используя пространства имен, метки, аннотации и т. д.
Его можно легко установить!
Chaos Monkey

Chaos Monkey – это инструмент, используемый для проверки устойчивости облачных систем путем преднамеренного создания сбоев в этих системах, чтобы понять их реакцию.
Netflix создал его для тестирования отказоустойчивости и возможности восстановления инфраструктуры AWS.
Он был назван Chaos Monkey, потому что он создает разрушения, как дикая вооруженная обезьяна, чтобы проверить ошибки.
Также именно Chaos Monkey положила начало новой инженерной практике Chaos Engineering.
Он был создан по принципу, что лучше тестировать сбои неоднократно, чтобы избежать внезапного серьезного отказа.
Simmy

Simmy – это инструмент хаос инжиниринга для внедрения ошибок, который интегрируется с проектом Polly для .NET.
Он позволяет вам создавать политики внедрения хаоса через Polly, где вы выполняете свой код.
Он предлагает различные политики, такие как политика исключений для внедрения исключений в систему, политика поведения для внедрения любого нового поведения и т. д.
Эти политики предназначены для случайного внедрения поведения.
Pystol

Pystol – это инструмент, который используется для внедрения ошибочных инъекций в облачных средах.
Он наблюдает за событиями в ETCD через операторов Kubernetes.
Когда выполняется действие по внедрению сбоя, операторы создают поды запускают несколько коллекций Ansible.
Таким образом, разработчикам не нужно писать собственные действия для выполнения в кластере.
Pystol предоставляет готовые действия для тестирования системы.
Тем не менее, если разработчик хочет создать новое действие, это можно сделать с помощью GoLang и Python.
Он предоставляет панель непрерывной интеграции, которая дает сводный обзор всех рабочих операций.
Вы можете запустить Pystol локально или развернуть его в контейнере с помощью образа Docker.
Pystol предоставляет два интерфейса: один – это веб-интерфейс, а другой – через интерфейс командной строки.
Очевидно, веб-интерфейс – лучший вариант.
Muxy
Muxy – это прокси для проверки ваших шаблонов отказоустойчивости при сбоях реальных распределенных систем.
Он может вмешиваться в транспортный уровень (уровень 4), сеансовый уровень TCP (уровень 5), уровень протокола HTTP (уровень 7).
Особенности Muxy:
- Модульная и легко расширяемая архитектура
- Имеет официальный Docker образ
- Простота установки, никаких зависимостей.
- Идеально подходит для непрерывного тестирования устойчивости
- Имитирует проблемы с сетевым подключением для распределенной системы и мобильных устройств.
Pumba

Pumba – это инструмент командной строки, который выполняет хаос тестирование для контейнеров Docker.
С помощью Pumba вы намеренно убиваете контейнеры, запускающие приложение, чтобы увидеть, как отреагирует система.
Вы также можете выполнить стресс-тестирование ресурсов контейнера, таких как ЦП, память, файловая система, ввод / вывод и т. д.
Вы также можете запустить Pumba в кластере Kubernetes.
Вы должны использовать DaemonSets для развертывания Pumba на нодах Kubernetes.
Вы можете использовать несколько контейнеров Pumba для выполнения нескольких команд Pumba в одном DaemonSet.
ChaosBlade

ChaosBlade – это инструмент с открытым исходным кодом для внедрения экспериментов в системы от Alibaba.
Он проверяет все сбои, с которыми Alibaba столкнулась за последние десять лет, и применяет передовые методы, чтобы их избежать.
Для проверки отказоустойчивости распределенных систем используются принципы хаос инженерии.
Litmus

Litmus следует принципам облачного хаос инжиниринга.
Миссия инструмента litmus – предоставить полную основу для поиска слабых мест в ваших системах Kubernetes и ваших запущенных приложениях на Kubernetes.
В нем есть оператор хаос и CRD (CustomResourceDefinitions), что обеспечивает возможность plug-and-play.
Особенности Litmus
- Помогает инженерам и разработчикам Site Reliability найти слабые места в системе Kubernetes.
- Предоставляет готовые к использованию общие эксперименты
- Предоставляет Chaos API для управления рабочим процессом
- Litmus SDK поддерживает Go, Python и Ansible для создания ваших собственных экспериментов.
Gremlin
Gremlin помогает инженерам создавать более устойчивое программное обеспечение.
Он предоставляет платформу для безопасного, надежного и простого проведения экспериментов по хаос инженирингу.
Вы можете внедрить хаос сбои на хосты или контейнеры с помощью gremlin независимо от того, где они находятся, будь то общедоступное облако или ваш собственный центр обработки данных.
Steadybit
Steadybit нацелен на упреждающее сокращение времени простоя и обеспечивает видимость системных проблем.
Вы можете запустить этот инструмент локально в своей инфраструктуре или в облаке как услуге (SaaS).
Чтобы использовать Steadybit, вы определяете ситуацию, моделируете эксперименты, выполняете моделируемые эксперименты на производстве и автоматизируете их.
Он запускает интеллектуальные агенты в вашей системе для обнаружения потенциальных проблем и слабых мест.
Он легко интегрируется с несколькими системами.
Заключение
Эти инструменты помогут вам найти несколько неопознанных слабых мест в вашей системе и помогут сделать ее более устойчивой.