
Существуют способы обнаружения скрытого или приватного содержимого, спрятанного на веб-сервере.
Давайте посмотрим, как можно обнаружить это неуловимое содержимое
Введение в обнаружение контента
Что такое обнаружение контента?
Обнаружение контента – это поиск контента, недоступного обычному пользователю, контента, к которому разработчики сайта не предполагали предоставлять вам доступ.
Это могут быть видеоролики, изображения, функции сайта, доступные только администраторам, скрытые данные и т.д.
Контент, не предназначенный для публичного доступа.
Старые версии сайта, конфигурационные файлы, функциональность, доступная (теоретически) только администраторам, панели администрирования и т.д. – все это можно и нужно попытаться обнаружить.
Существует три способа обнаружения контента на сайте: Ручной, автоматизированный и OSINT (Open-Source INTelligence).
Ручное обнаружение
Это делается нами без каких-либо программ или кодов.
Только старая добрая клавиатура и мышь.
Robots.txt
Файл robots.txt – это документ, указывающий поисковым системам, какие страницы разрешено и запрещено индексировать, или даже запрещать конкретным поисковым системам.
Это обычная практика для ограничения определенных областей сайта, таких как административные порталы или файлы, не предназначенные для обычных пользователей сайта:
Таким образом, мы получаем интересный список мест, которые владельцы сайта не хотят, чтобы люди открывали, но которые довольно полезны для нас.
🤖 Используем файл robots.txt для предотвращения индексации различных областей вашего сайта.
Обычно в корне сайта мы можем попытаться получить доступ к файлу, добавив /robots.txt к сайту, который мы пытаемся атаковать.
Например, проверим https://www.yandex.ru/robots.txt:
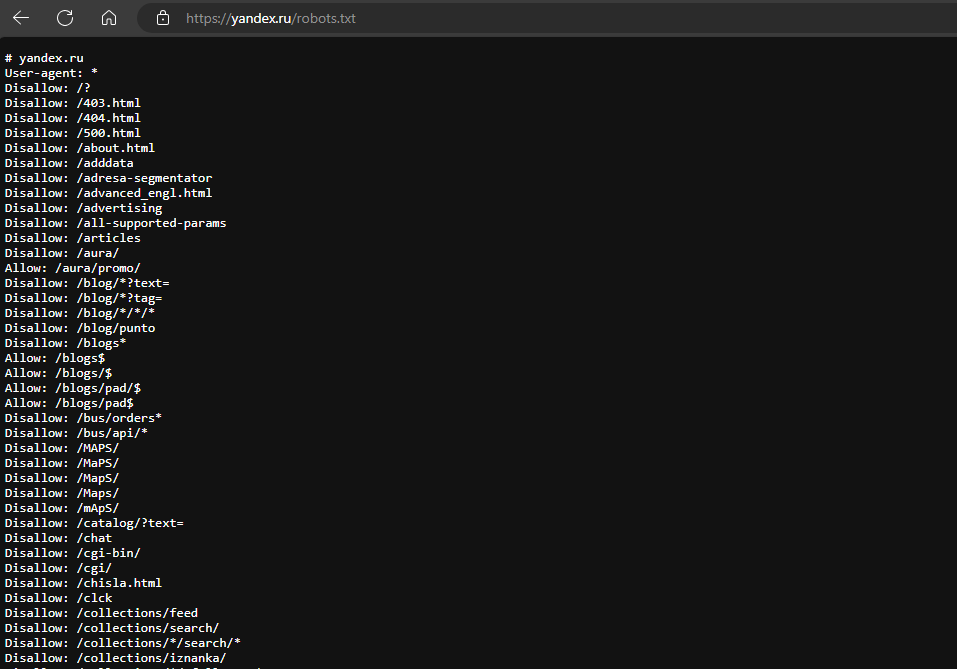
И этот список можно продолжать и продолжать.
Если бы мы были настолько безумны, чтобы атаковать yandex/ru, есть целый список мест, куда можно ткнуть пальцем.
Фавикон
Favicon – это небольшой значок, отображаемый рядом с адресной строкой браузера:
Вы можете подумать: Почему меня это должно волновать? Это же просто иконка!
И вы правы: это всего лишь иконка.
Значок, который, если веб-разработчик не изменил его, может подсказать нам, какой фреймворк он использует.
OWASP, Открытый всемирный проект по безопасности приложений (некоммерческая организация, занимающаяся повышением безопасности программного обеспечения), содержит базу данных фавиконов распространенных фреймворков, которую можно использовать для проверки найденного вами фавикона.
Например, если мы зайдем на этот сайт, и его favicon рядом с URL.
Рассмотрим код:
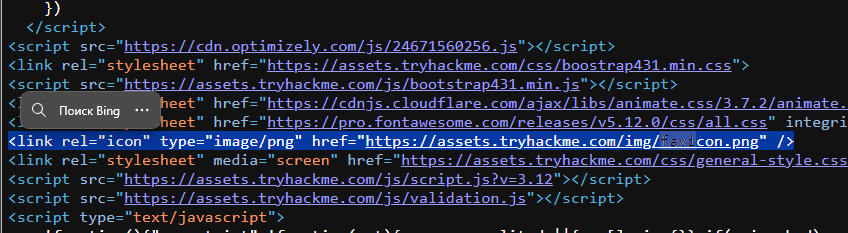
Получим хэш md5 (Message Digest algorithm, то, что используется для аутентификации) на терминале с помощью:
Шифрование и Хэширование. Отличие и применение
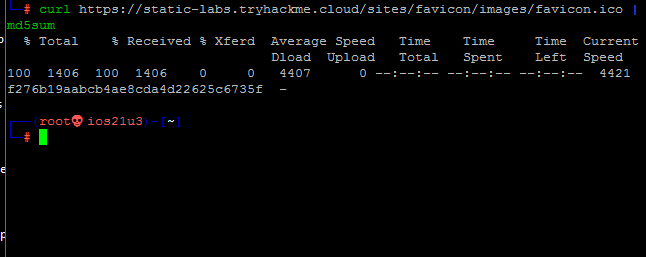
Выполним поиск этого хэша в базе данных OWASP:
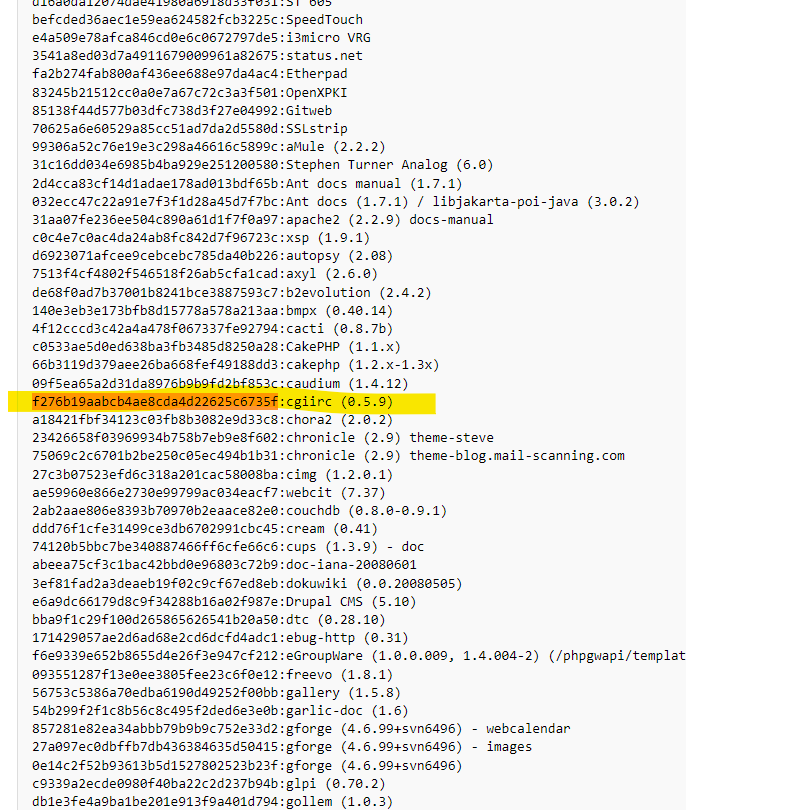
Это нечто, называемое cgiirc, давайте сделаем быстрый поиск в Google:
Отлично, теперь мы знаем, на что нападать!
sitemap.xml
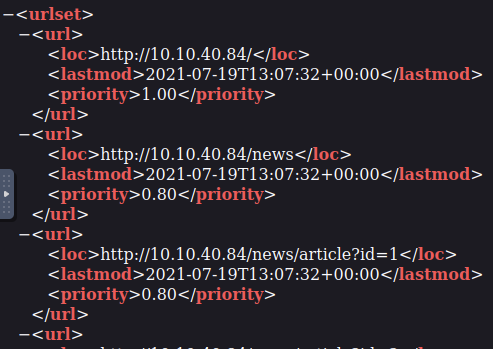
В то время как robots.txt ограничивает возможности поисковых систем, sitemap.xml содержит список всех файлов, которые веб-разработчик хотел бы включить в список.
Иногда он содержит области сайта, по которым трудно ориентироваться, или даже перечисляет старые веб-страницы или ресурсы, которые сайт больше не использует, но они все еще доступны.
Рассмотрим пример XML:
HTTP-заголовки
При запросах к веб-серверу сервер возвращает HTTP-заголовки.
Эти заголовки иногда могут содержать важную информацию, например, какое серверное программное обеспечение используется, какой язык программирования используется, IP-адрес машины и т.д.
Рассмотрим пример:
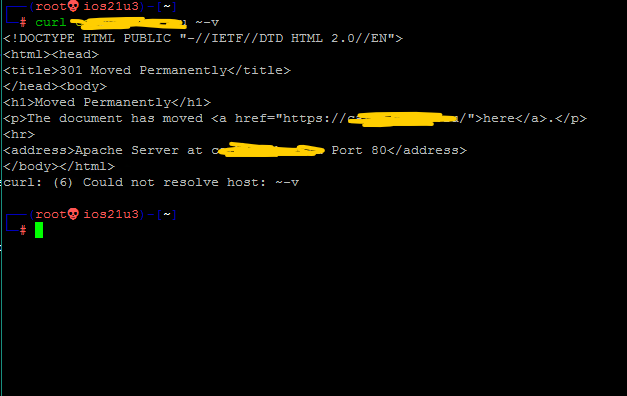
Здесь мы видим, что веб-сервер использует Apache.
Стек фреймворков
После того как мы узнали, какой фреймворк используется на сайте, проверив favicon, прочитав исходный код или поискав подсказки в комментариях, титрах или разделах сайта, мы можем обратиться к сайту фреймворка для получения дополнительной информации.
OSINT
Существуют также внешние источники, которые могут помочь нам получить информацию о нашей цели.
Эти ресурсы называются OSINT (Open Source INTelligence), и они бесплатны:
Google Hacking/Dorking
Google-хакинг, или доркинг, использует расширенные функции поиска Google, которые позволяют улучшить качество поиска.
Вы можете использовать фильтры (один или несколько одновременно), чтобы сделать поиск более точным.
Рассмотрим некоторые распространенные фильтры
- site -> site:reddit.com Еда -> Выполняется поиск только по теме ‘Еда’ на сайте Reddit.com
- inurl -> inurl:admin -> Возвращает результаты, в URL которых есть ‘admin’
- filetype -> filetype:pdf Socrates -> Возвращает PDF-файлы, в тексте которых есть Сократ
- intitle -> intitle:admin -> Возвращает результаты, содержащие в заголовке слово ADMIN
Wappalyzer
Wappalyzer – это онлайн-инструмент и расширение для браузера, позволяющее определить, какие технологии (язык программирования, фреймворк и т.д.) использует тот или иной сайт.
Довольно полезная вещь, если вы ленивы (как и должно быть).
Wayback Machine
Wayback Machine – это исторический архив веб-сайтов.
Вы можете задать поиск по доменному имени, и он покажет вам все случаи, когда сервис делал снимок этой веб-страницы.
Представьте себе, как выглядел Twitter в 2009 или 2014 году!
GitHub
Git – это система контроля версий, которая отслеживает изменения файлов в проекте локально.
GitHub – это размещенная в Интернете версия Git.
Репозитории могут быть публичными или частными.
Вы можете использовать функцию поиска GitHub по названиям компаний или сайтов, чтобы попытаться найти репозитории, принадлежащие вашей цели.
Если они будут найдены, вы сможете получить доступ к их исходному коду, а иногда и к паролям и другому содержимому.
- ⚓ Github-Dorks – Коллекция Github дорков и вспомогательного инструмента для автоматизации процесса проверки
- 🔎 yar: инструмент OSINT для разведки репозиториев / пользователей / организаций на Github
Бакеты S3
S3 – это сервис хранения данных, предоставляемый компанией Amazon AWS, который позволяет сохранять файлы и статические веб-сайты.
Владелец файлов может устанавливать права доступа, делая файлы общедоступными, закрытыми или доступными для записи.
При неправильной настройке прав доступа мы можем получить доступ к файлам, к которым не должны.
URL-адрес – http(s)://{name}.s3.amazonaws.com, где {name} определяется владельцем.
Мы можем обнаружить S3, найдя URL в источнике страницы сайта, репозиториях GitHub или даже автоматизировав этот процесс.
Автоматизированное обнаружение
Автоматизированное обнаружение – это процесс обнаружения содержимого с помощью средств программирования (программы, скрипта и т.д.).
Обычно этот процесс состоит из сотен, тысяч и более миллионов запросов к веб-серверу на предмет существования файла или каталога, в результате чего обнаруживается содержимое, к которому мы не должны иметь доступа.
Иногда в этом процессе используются списки слов: текстовый файл, содержащий длинный (тысячи и более) список часто используемых слов. Например, список слов-паролей содержит наиболее часто используемые пароли, а список слов-файлов – наиболее часто используемые имена файлов.
Средства автоматизации
Существует множество средств автоматизации, каждое из которых обладает своими возможностями.
Рассмотрим три из них: ffuf, dirb и GoBuster:
¯\_(ツ)_/¯
Примечание: Информация для исследования, обучения или проведения аудита. Применение в корыстных целях карается законодательством РФ.







