
Приветствую, ребята! Здесь я представляю вам наиболее эффективный и удивительный способ мониторинга инфраструктуры VMware ESXi с помощью Grafana, Telegraf и InfluxDB.
Настройка довольно проста, и вы должны визуализировать свои показатели VMware на Grafana менее чем за 30 минут.
Эта установка использует официальный плагин vSphere для Telegraf для извлечения метрик из vCenter.
Сюда входят показатели для вычислений хостов vSphere (RAM и CPU), сетей, хранилищ данных и виртуальных машин, работающих на гипервизорах vSphere.
Итак, начнем.
Шаг 1: Установите InfluxDB и Grafana
Все собранные метрики хранятся в базе данных InfluxDB.
Grafana подключится к InfluxDB для запроса и отображения метрик на своих инструментальных панелях.
Вам нужно установить оба инструмента – InfluxDB и Grafana перед продолжением.
Как установить InfluxDB на Ubuntu и CentOS
Как только InfluxDB и Grafana установлены, приступайте к установке и настройке Telegraf, который является мощным сборщиком метрик, написанным на Go.
Шаг 2. Установите и настройте Telegraf
Если вы использовали ссылки на шаге 1 для установки InfluxDB, был добавлен репозиторий, необходимый для установки Telegraf.
Просто используйте следующие команды для установки Telegraf.
# CentOS sudo yum -y install telegraf # Ubuntu sudo apt-get -y install telegraf
После установки нам нужно настроить Telegraf на получение метрик мониторинга из vCenter.
Отредактируйте основной конфигурационный файл Telegraf:
sudo vim /etc/telegraf/telegraf.conf
1. Добавьте выходной сервер хранения InfluxDB, где будут храниться метрики.
# Configuration for sending metrics to InfluxDB
[[outputs.influxdb]]
urls = ["http://10.10.1.20:8086"]
database = "vmware"
timeout = "0s"
username = "monitoring"
password = "DBPassword"Замените 10.10.1.20 IP-адресом вашего сервера InfluxDB. если у вас не включена аутентификация на InfluxDB, вы можете безопасно удалить строку имени пользователя и пароля в конфигурации.
2. Настройте входной плагин vsphere для Telegraf. Полная конфигурация должна выглядеть примерно так:
# Read metrics from VMware vCenter [[inputs.vsphere]] ## List of vCenter URLs to be monitored. These three lines must be uncommented ## and edited for the plugin to work. vcenters = [ "https://10.10.1.2/sdk" ] username = "administrator@vsphere.local" password = "AdminPassword" # ## VMs ## Typical VM metrics (if omitted or empty, all metrics are collected) vm_metric_include = [ "cpu.demand.average", "cpu.idle.summation", "cpu.latency.average", "cpu.readiness.average", "cpu.ready.summation", "cpu.run.summation", "cpu.usagemhz.average", "cpu.used.summation", "cpu.wait.summation", "mem.active.average", "mem.granted.average", "mem.latency.average", "mem.swapin.average", "mem.swapinRate.average", "mem.swapout.average", "mem.swapoutRate.average", "mem.usage.average", "mem.vmmemctl.average", "net.bytesRx.average", "net.bytesTx.average", "net.droppedRx.summation", "net.droppedTx.summation", "net.usage.average", "power.power.average", "virtualDisk.numberReadAveraged.average", "virtualDisk.numberWriteAveraged.average", "virtualDisk.read.average", "virtualDisk.readOIO.latest", "virtualDisk.throughput.usage.average", "virtualDisk.totalReadLatency.average", "virtualDisk.totalWriteLatency.average", "virtualDisk.write.average", "virtualDisk.writeOIO.latest", "sys.uptime.latest", ] # vm_metric_exclude = [] ## Nothing is excluded by default # vm_instances = true ## true by default # ## Hosts ## Typical host metrics (if omitted or empty, all metrics are collected) host_metric_include = [ "cpu.coreUtilization.average", "cpu.costop.summation", "cpu.demand.average", "cpu.idle.summation", "cpu.latency.average", "cpu.readiness.average", "cpu.ready.summation", "cpu.swapwait.summation", "cpu.usage.average", "cpu.usagemhz.average", "cpu.used.summation", "cpu.utilization.average", "cpu.wait.summation", "disk.deviceReadLatency.average", "disk.deviceWriteLatency.average", "disk.kernelReadLatency.average", "disk.kernelWriteLatency.average", "disk.numberReadAveraged.average", "disk.numberWriteAveraged.average", "disk.read.average", "disk.totalReadLatency.average", "disk.totalWriteLatency.average", "disk.write.average", "mem.active.average", "mem.latency.average", "mem.state.latest", "mem.swapin.average", "mem.swapinRate.average", "mem.swapout.average", "mem.swapoutRate.average", "mem.totalCapacity.average", "mem.usage.average", "mem.vmmemctl.average", "net.bytesRx.average", "net.bytesTx.average", "net.droppedRx.summation", "net.droppedTx.summation", "net.errorsRx.summation", "net.errorsTx.summation", "net.usage.average", "power.power.average", "storageAdapter.numberReadAveraged.average", "storageAdapter.numberWriteAveraged.average", "storageAdapter.read.average", "storageAdapter.write.average", "sys.uptime.latest", ] # host_metric_exclude = [] ## Nothing excluded by default # host_instances = true ## true by default # ## Clusters cluster_metric_include = [] ## if omitted or empty, all metrics are collected # cluster_metric_exclude = [] ## Nothing excluded by default # cluster_instances = false ## false by default # ## Datastores datastore_metric_include = [] ## if omitted or empty, all metrics are collected # datastore_metric_exclude = [] ## Nothing excluded by default
# datastore_instances = false ## false by default for Datastores only # ## Datacenters datacenter_metric_include = [] ## if omitted or empty, all metrics are collected datacenter_metric_exclude = [ "*" ] ## Datacenters are not collected by default. # datacenter_instances = false ## false by default for Datastores only # ## Plugin Settings ## separator character to use for measurement and field names (default: "_") # separator = "_" # ## number of objects to retreive per query for realtime resources (vms and hosts) ## set to 64 for vCenter 5.5 and 6.0 (default: 256) # max_query_objects = 256 # ## number of metrics to retreive per query for non-realtime resources (clusters and datastores) ## set to 64 for vCenter 5.5 and 6.0 (default: 256) # max_query_metrics = 256 # ## number of go routines to use for collection and discovery of objects and metrics # collect_concurrency = 1 # discover_concurrency = 1 # ## whether or not to force discovery of new objects on initial gather call before collecting metrics ## when true for large environments this may cause errors for time elapsed while collecting metrics ## when false (default) the first collection cycle may result in no or limited metrics while objects are discovered # force_discover_on_init = false # ## the interval before (re)discovering objects subject to metrics collection (default: 300s) # object_discovery_interval = "300s" # ## timeout applies to any of the api request made to vcenter # timeout = "60s" # ## Optional SSL Config # ssl_ca = "/path/to/cafile" # ssl_cert = "/path/to/certfile" # ssl_key = "/path/to/keyfile" ## Use SSL but skip chain & host verification insecure_skip_verify = true
Единственные переменные, которые нужно изменить с вашей стороны:
- 10.10.1.2 следует заменить на IP-адрес vCenter
- administrator@vsphere.local должен соответствовать вашей учетной записи vCenter
- AdminPassword паролем для аутентификации
Если ваш сервер vCenter имеет самоподписанный сертификат, убедитесь, что вы включили insecure_skip_verify flag на true
insecure_skip_verify = true
Запустите и включите услугу телеграф после внесения изменений.
sudo systemctl restart telegraf sudo systemctl enable telegraf
Шаг 3: Проверьте показатели InfluxDB
Мы должны подтвердить, что наши показатели передаются в InfluxDB и что мы можем их видеть.
Откройте оболочку InfluxDB:
С аутентификацией:
$ influx -username 'username' -password 'StrongPassword' Connected to http://localhost:8086 version 1.6.4 InfluxDB shell version: 1.6.4
‘Username‘ – имя пользователя для аутентификации InfluxDB
SRong StrongPassword ‘- пароль InfluxDB
Без аутентификации:
$ influx Connected to http://localhost:8086 version 1.6.4 InfluxDB shell version: 1.6.4
Переключитесь на базу данных vmware, которую мы настроили на telegraf.
> USE vmware Using database vmware
Проверьте, есть ли приток метрик временных рядов.
> SHOW MEASUREMENTS
name: measurements
name
----
cpu
disk
diskio
kernel
mem
processes
swap
system
vsphere_cluster_clusterServices
vsphere_cluster_mem
vsphere_cluster_vmop
vsphere_datacenter_vmop
vsphere_datastore_datastore
vsphere_datastore_disk
vsphere_host_cpu
vsphere_host_disk
vsphere_host_mem
vsphere_host_net
vsphere_host_power
vsphere_host_storageAdapter
vsphere_host_sys
vsphere_vm_cpu
vsphere_vm_mem
vsphere_vm_net
vsphere_vm_power
vsphere_vm_sys
vsphere_vm_virtualDisk
> Шаг 3: Добавить источник данных InfluxDB в Grafana
Войдите в Grafana и добавьте источник данных InfluxDB.
Укажите IP-адрес сервера, имя базы данных и учетные данные для аутентификации, если применимо.

Дайте ему имя, выберите тип, укажите IP-адрес сервера.
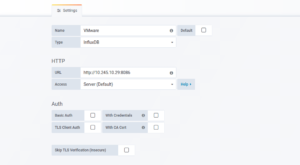
Укажите имя базы данных и учетные данные для аутентификации, если применимо.

Сохраните и проверьте настройки.

Шаг 4: Импорт информационных панелей Grafana
Мы настроили все зависимости и протестировали работу.
Последнее действие – создать или импортировать информационные панели Grafana, которые будут отображать метрики vSphere.
- Grafana vSphere Overview Dashboard – 8159
- Grafana vSphere Datastore Dashboard – 8162
- Grafana vSphere Hosts Dashboard – 8165
- Grafana vSphere VMs Dashboard – 8168








Я правильно понял, что это все возможно только с vCenter? С ESXi напрямую это не работает?
Скорее всего можно и через esxi, но опыта нету.